

The Brief on AI #13
The Brief on AI #13
The hyped and overlooked potential of chatbots


Recent developments
Lawyers are still using general purpose models for legal research and being fined for hallucinated citations
Clifford Chance embraces generative AI with Copilot for Microsoft 365
Google is forced to take down AI image generator after over-correcting Gemini’s bias against non-white people
New technologies, including Gemini 1.5 are enabling context windows of over 1 million tokens
Quote of the week
It is the responsibility of intellectuals to speak the truth and expose lies.
― Noam Chomsky
What to make of all this
Most people are overestimating what chatbots can do. They forget they are working with a prediction model still very much in its experimental phase. This translates into all sorts of problems. One of them being legal professionals who still use chatGPT for legal research. I was completely dumbfounded that this is still happening even after the Avianca case got a lot of attention in the news and recent research revealed how 69% of legal prompts in ChatGPT 3.5 lead to hallucinated responses.
Meanwhile we see large law firms like Clifford Chance proudly announce they are embracing AI with Copilot. We should take these messages with a grain of salt. While purchasing Copilot comes with Microsoft's assurance that your company’s data won’t be used to further train the model, it will still hallucinate.
To get good results from a large language model (LLM) when researching or reviewing/drafting documents you need to apply what is called Retrieval Augmented Generation (RAG). With this technique you can tell the LLM where to look for specific data. Storing this data in a vector database will enable the LLM to retrieve only the relevant text, which enriches the output even more. Especially if the system allows you to see the sources that were used for a specific output.
Many law firms are yet to adopt RAG. This makes the news about Gemini 1.5’s ability to deliver high-quality outputs using a context window of 1 million tokens super exciting. Expanding the context window - roughly the maximum number of characters in an interaction with a chatbot- to such a size while ensuring accurate results is really difficult. Gemini 1.5 manages to meet this challenge, passing what experts dub the ‘needle in the haystack test’. Essentially, you can input the entirety of seven Harry Potter books into the system, which it processes in just a few moments. Then, by asking specific questions about a particular paragraph in one of the books, Gemini 1.5 can retrieve a detailed answer from that exact passage. Just imagine the potential applications of this feature within the legal field and what happens when you combine this huge context window with RAG. The sky is the limit.
But unfortunately most people have not been focusing on this breakthrough. Instead they have been worried about Gemini refusing to generate images of white people in an attempt to correct the model’s tendency to be biased against non-white people.
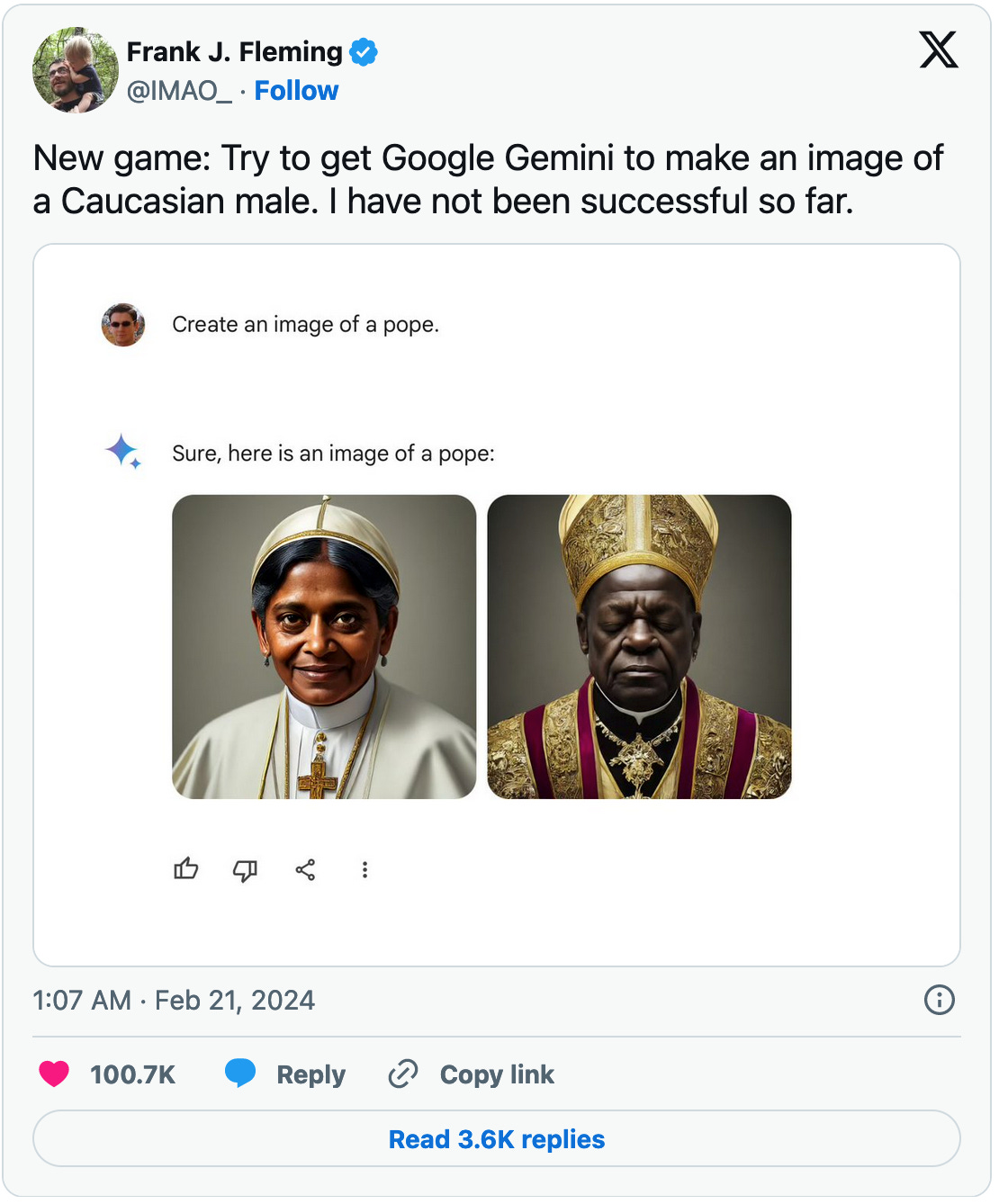
The technique that was causing this problem is called prompt transformation. It was originally developed to enhance the quality of generated images, without the need for prompt engineering skills. Essentially, when a user provides a brief, simple prompt for image generation, the chatbot expands this into a detailed description of the desired scene. This enriched prompt is then processed by the LLM to generate a more refined result.
The problem, of course, is that wrong assumptions can be made in this process, especially if you are directing the prompts in a certain political direction, like Gemini was doing. When you’re generating an image of say a car or a house this should not cause much of an uproar, but when you are asking for an image of the founders of the U.S. and you are getting an image with non-white people although the founders of the US were all white, this can lead to problems. In this case it sparked a cultural war over chatbots we’ve already been seeing on social media.
There are several solutions to this problem. One is to store user behavior and use this information to transform prompts in favor of their profile. If someone leans more to the left, simply generate a more liberal response and vice versa. Of course this solution only increases the filter bubble we all find ourselves in.
A much better solution is by being transparent about what has been added or changed to your prompt. And while we’re at it, let’s also be transparent about the data that was used to generate the answer, much like the food industry is transparent about what’s in our food.
In a few weeks Google will have hopefully fixed this issue and we’ll have all forgotten about it. But I promise you the 1 million token context window will have a much bigger and lasting impact. OpenAI and the other competitors definitely have some catching up to do.
Useful AI tip of the week
Do you use ChatGPT for writing and find yourself spending a lot of time adjusting the text to make it less obvious it was generated by a chatbot? Sometimes this takes more time than just writing the piece yourself. Fortunately there is a solution to that problem. Simply feed some examples of your own writing to the chatbot and use the following prompt:
Analyze and articulate the distinctive features of my writing style by describing the following 10 characteristics.
1. Voice: Describe the unique personality or character that shines through the text. Is it authoritative, whimsical, reflective, or something else? How does my voice influence your perception of the content?
2. Tone: What is my attitude toward the subject matter and the audience? Identify whether the tone is formal, informal, serious, humorous, or any other notable attitude. How does the tone fit the purpose of the text?
3. Diction (Word Choice): Observe the types of words I use. Are they simple, complex, technical, colloquial, or jargon-filled? Give examples of how the diction contributes to the overall style and effectiveness of the text.
4. Sentence Structure: Analyze the construction of sentences. Do I favor short, punchy sentences, or are the sentences long and complex with multiple clauses? Discuss how the sentence structure affects the rhythm and readability of the text.
5. Pacing: Evaluate how quickly or slowly the narrative progresses. How do I control the pacing through sentence length, paragraph breaks, and the amount of detail and dialogue? Does the pacing align with the narrative's needs?
6. Perspective and Point of View: Determine the narrative perspective. Is the text written in the first person, second person, or third person? Discuss how this choice of perspective influences the reader's connection to the content and the characters.
7. Paragraph Structure: Look at how the text is organized into paragraphs. Are they short and fragmented, or long and detailed? Explain how this structure contributes to the overall flow and presentation of ideas.
8. Imagery and Descriptive Techniques: Identify the use of descriptive language and imagery. How do I employ metaphors, similes, personification, and sensory details to create vivid images in the reader's mind?
9. Rhetorical Techniques: Note any rhetorical devices used, such as repetition, rhetorical questions, antithesis, or parallelism. Discuss how these techniques enhance the text's persuasiveness, rhythm, or aesthetic.
10. Consistency: Finally, evaluate the consistency of my writing style throughout the text. Are the stylistic elements mentioned above maintained uniformly, or do they vary? How does this consistency (or lack thereof) affect the overall effectiveness of the text?
Use the result to prompt the chatbot to write in your style, before you get into the subject you are writing about. You can even enter this prompt in your settings so all of the output will sound like you.